In the past 2016, in the computer industry, I believe that no concept is more popular than artificial intelligence. Entering 2017, experts say that the demand for artificial intelligence ecosystems will grow even more rapidly. Mainly focused on finding the "engine" that is more suitable for deep neural networks for performance and efficiency.
Today's deep learning systems rely on software-defined networks and the sheer computing power of big data learning to achieve their goals. Unfortunately, this type of computing configuration is difficult to embed in systems where computing power, storage size, and bandwidth are limited (such as cars, drones, and IoT devices).
This presents a new challenge for the industry, how to embed the computing power of deep neural networks into terminal devices through innovation.
Movidius CEO Remi El-Ouazzane said a few months ago that placing artificial intelligence on the edge of the network would be a big trend.
When asked why artificial intelligence was “rushed†to the edge of the network, CEA Architecture Fellow Marc Duranton gave three reasons: security, privacy, and economy. He believes that these three points are important factors driving the industry to process data at the terminal. He pointed out that in the future, there will be more demand for “transforming data into informationâ€. And the sooner these data are processed, the better, he added.

CEA Architecture Fellow Marc Duranton
Camera, if your driverless car is safe, then these unmanned functions do not need to rely on the alliance for a long time; if the old man falls at home, then this situation should be detected and judged on the spot. These are very important for privacy reasons, Duranton stressed.
But this does not mean that all the pictures of the ten cameras in the home are collected and sent to me, which is called a reminder of a number. This does not reduce "energy, cost and data size," Duranton added.
The competition officially openedFrom the current situation, chip suppliers have realized the growing demand for inference engines. Many semiconductor companies, including Movidus (Myriad 2), Mobileye (EyeQ 4 & 5) and Nvidia (Drive PX), are competing for low-power, high-performance hardware accelerators. Help developers better perform "learning" in embedded systems.
From the perspective of the actions of these vendors and the development direction of SoC, in the post-smartphone era, the inference engine has gradually become the next target market pursued by semiconductor manufacturers.
Earlier this year, Google's TPU turned out to be an indication of the industry's intention to drive innovation in Machine learning chips. When the chip was released, the search giant said that the performance per watt of TPU would be an order of magnitude higher than that of traditional FPGAs and GPUs. Google also said that the accelerator has also been applied to the AlphaGo system, which was popular around the world earlier this year.
But since its release, Google has never disclosed the specifics of TPU, let alone sell it.
Many SoC practitioners have come to the conclusion from Google's TPU that they believe that machine learning requires a customized architecture. But when they do chip design for machine learning, they are doubtful and curious about the architecture of the chip. At the same time, they want to know if the industry already has a tool to measure the performance of deep neural networks (DNN) in different forms.
Tools have arrivedCEA claims that they have prepared for the inference engine to explore different hardware architectures, and they have developed a software architecture called N2D2. They are enough to help designers explore and claim the DNN architecture. "We developed this tool to help DNN choose the right hardware," Duranton said. By the first quarter of 2017, this N2D2 will be open source. Duranton promised.
N2D2 is characterized by not only comparing hardware based on recognition accuracy, but also comparing it in terms of processing time, hardware cost and energy loss. Because the hardware configuration parameters required for different deep learning applications are different, so the above points are the most important, Duranton said.
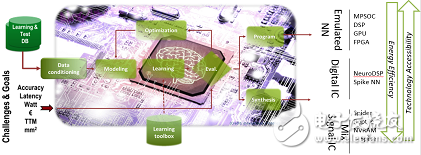
How N2D2 works
N2D2 provides a reference standard for existing CPUs, GPUs, and FPGAs.
Barriers to edge computingAs a senior research organization, CEA has conducted in-depth research on how to extend DNN to the field of edge computing. When asked about the obstacles to this kind of advancement, Duranton pointed out that these "floating point" server solutions cannot be applied due to power consumption, size and latency limitations. This is the biggest obstacle. Other obstacles include "a large number of Macs, bandwidth and size on the chip," Duranton added.
That is to say how to integrate this "floating point" method is the first problem that should be solved.
Duranton believes that some new architectures are inevitable, and some new coding like "spike code" is inevitable.
According to CEA research, even binary encoding is not required. They believe that time coding like spike coding can emit more powerful energy at the edge.
Spike coding is popular because it clearly demonstrates the decoding of data within the nervous system. In the deepest sense, these event-based encodings are compatible with dedicated sensors and pre-processing.
This extremely similar encoding to the nervous system makes hybrid analog and digital signals easier to implement, which also helps researchers create low-power hardware accelerators.
CEA is also thinking about the potential to adjust the neural network architecture to edge computing. Duranton pointed out that people are now pushing to use 'SqueezeNet to replace AlexNet. According to reports, in order to achieve the same accuracy, the former uses 50 times less parameters than the latter. This type of simple configuration is important for edge computing, topology, and reducing the number of Macs.
Duranton believes that moving from a classic DNN to an embedded network is a spontaneous act.
P-Neuro, a temporary chipCEA's ambition is to develop a neuromorphic circuit. Researchers believe that such a chip is an effective complement to push data extraction on the sensor side in deep learning.
But before reaching this goal, CEA got along with a lot of expediency. For example, the development of tools such as D2N2 helps chip developers develop high-TOPS DNN solutions.
For those who want to transfer DNN to edge computing, they also have the corresponding hardware to implement. This is the low-power programmable accelerator from CEA, P-Neuro. The current P-Neuro chip is based on FPGA development. But Duranton said they have turned this FPAG into an ASIC.
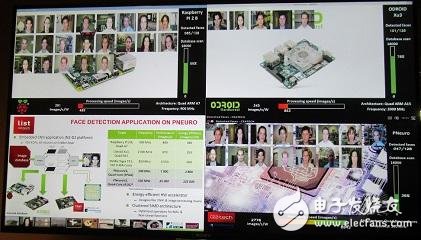
P-Neuro demo compared to embedded CPU
In CEA's lab, Duranton has built a facial recognition convolutional neural network (CNN) in this FPAG-based P-Neuro. This P-Neuro-based demo is compared to the embedded CPU. (Raspberry pie, Android device with Samsung Exynos processor). They also all run the same CNN application. They all arranged to perform "face feature extraction" from a database of 18,000 images.
According to the example, the speed of P-Neuro is 6,942 images per second, while the power consumption is only 2,776 images per watt.
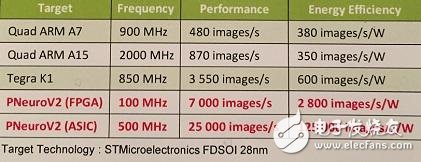
P-Neuro and GPU, CPU comparison
As shown, the FPGA-based P-Neuro works faster and consumes less power at 100Mhz operating frequency than the Tegra K1.
P-Neuro is built on a cluster-based SIMD architecture that is well known for its optimized hierarchical memory architecture and internal connectivity.
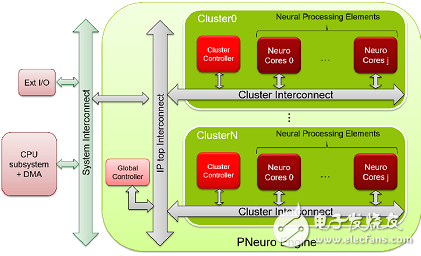
Block diagram of P-Neuro
For CEA researchers, P-Neuro is only a short-term solution. The current P-Neuro is built on a CMOS device using binary encoding. Their team is building a full CMOS solution and is planning to use spike coding.
In order to take full advantage of the advantages of advanced equipment and break the issue of density and power, their team set a higher goal. They considered RRAM as a synapse element and considered processes such as FDSOI and nanowires.
In a "EU Horizon 2020" program, they hope to make a neuromorphic architecture chip that can support the most advanced machine learning. It is also a spike-based learning mechanism.
Neuromorphic processorThis is a project called NeuRAM3. By then, their chips will have ultra-low power, size and highly configurable neural architecture. Their goal is to create a product that can reduce power consumption by a factor of 50 compared to traditional solutions.
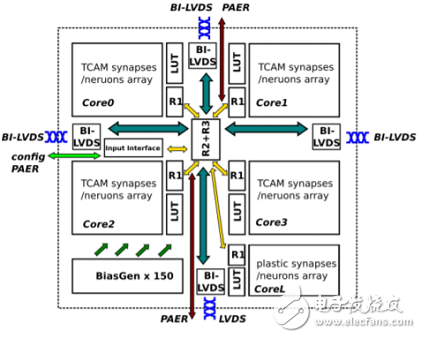
Neuromorphic processor
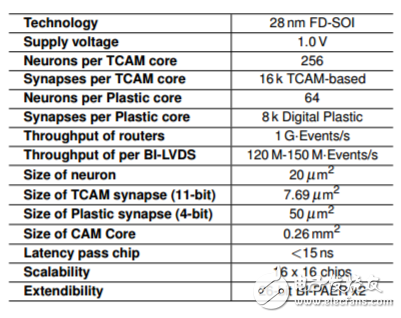
Basic parameters of the Neuromorphic processor
According to reports, this solution includes the integrated 3D technology based on the FD-SOI process, and also uses RRAM to make synaptic elements. Under the NeuRAM3 project, this new mixed-signal multi-core neuromorphic chip device can significantly reduce power consumption compared to IBM's TrueNorth.
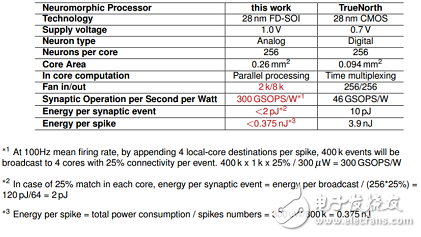
Contrast with IBM's TrueNorth
Participants in the NeuRAM3 project include IMEC, IBM Zurich, ST Microelectronics, CNR (The NaTIonal Research Council in Italy), IMSE (El InsTItuto de Microelectrónica de Sevilla in Spain), the University of Zurich and the University of Jacobs in Germany.
More AI chip competitionIn fact, the AI ​​chip market has attracted a lot of players, both traditional semiconductor manufacturers and so-called start-ups, have begun to go to this next gold mine. In addition to the CEA mentioned above. Let's take a look at what other AI chips are on the market.
First, the follow-up of traditional manufacturers(1) Nvidia
NVIDIA is the GPU overlord. Although they missed the mobile era, they seem to have regained their glory in the AI ​​era. From the stock trend in the past year, they can see the confidence of the market. Let's see what plans he has in this area.
In April of this year, Nvidia released an advanced machine learning chip, the Tesla P100 GPU. According to Nvidia CEO Huang Renxun, this product has 12 times faster processing speed than NVIDIA's predecessor. The $2 billion developed chip integrates 150 billion transistors. According to reports, the new NVIDIA PascalTM architecture enables the Tesla P100 to deliver exceptional performance for HPC and very large workloads. With more than 20 trillion FP16 floating-point performance per second, the optimized Pascal brings exciting new possibilities for deep learning applications.

By adding CoWoS (wafer-based chip) technology using HBM2, the Tesla P100 tightly integrates computing and data in the same package with more than three times the memory performance of previous generation solutions. This allows the problem-solving time of data-intensive applications to leapfrog across the ages.
In addition, thanks to NVIDIA NVLinkTM technology, the Tesla P100's fast nodes can significantly reduce the time it takes to provide solutions for applications with strong scalability. Server nodes with NVLink technology can interconnect up to eight Tesla P100s with 5x PCIe bandwidth. This design is designed to help solve the globally significant challenges of HPC and deep learning with significant computing needs.
(2) Intel
In November of this year. Intel has released an AI processor called Nervana, which they claim will test the prototype in the middle of next year. If all goes well, the final form of the Nervana chip will be available in 2017. The chip is based on a company called Nervana that Intel bought earlier. According to Intel, the company is the first company on the planet to build chips for AI.
Intel disclosed some details about the chip. According to them, the project code is "Lake Crest" and will use Nervana Engine and Neon DNN related software. . The chip accelerates a variety of neural networks, such as the Google TensorFlow framework. The chip consists of a so-called "processing cluster" array that handles simplified mathematical operations called "active points." This method requires less data than floating-point operations, resulting in a 10x performance boost.
Lake Crest uses private data connections to create larger, faster clusters with a circular or other topology. This helps users create larger, more diverse neural network models. This data connection contains 12 100Gbps bidirectional connections, and its physical layer is based on 28G serial-to-parallel conversion.
The 2.5D chip is equipped with 32GB of HBM2 memory and has a memory bandwidth of 8Tbps. There is no cache in the chip, and the software is used to manage on-chip storage.
Intel did not disclose the future roadmap for this product, only that it plans to release a version called Knights Crest. This version will integrate future Xeon processors and Nervana acceleration processors. This is expected to support the Nervana cluster. However, Intel did not disclose how and when these two types of chips will be integrated.
As for the integrated version, there will be more performance and easier programming. Current graphics processing chip (GPU)-based accelerated processors make programming more complicated because developers maintain separate GPU and CPU memory.
According to reports, by 2020, Intel will launch chips to improve the performance of neural network training by 100 times. One analyst said the goal was "extremely radical." There is no doubt that Intel will quickly move this architecture to more advanced manufacturing processes, competing with GPUs that already use 14nm or 16nm FinFET processes.
(3) IBM
Centennial giant IBM, who published wtson a long time ago, has now invested in a lot of research and development. In the past year, he also couldn't help but invest in the research and development of human brain chips. That is TrueNorth.
TrueNorth is the latest achievement of IBM's participation in DARPA's research project, SyNapse. SyNapse's full name is Systems of Neuromorphic AdapTIve PlasTIc Scalable Electronics, and SyNapse is synaptic. The ultimate goal is to develop hardware that breaks the von Neumann system.
This chip treats the digital processor as a neuron and uses memory as a synapse. Unlike traditional von Neumann architecture, its memory, CPU and communication components are fully integrated. Therefore, the processing of information is completely local, and since the amount of data processed locally is not large, the bottleneck between the traditional computer memory and the CPU no longer exists. At the same time, neurons can communicate with each other conveniently and quickly. As long as they receive pulses (action potentials) from other neurons, these neurons will act simultaneously.
In 2011, IBM first introduced a single-core chip prototype with 256 neurons, 256 × 256 synapses and 256 axons. The prototype at the time was already able to handle complex tasks like playing Pong games. However, it is relatively simple. In terms of scale, such a single-core brain capacity is only equivalent to the level of the brain.
However, after three years of hard work, IBM finally made a breakthrough in complexity and usability. 4096 cores, 1 million "neurons", 256 million "synapses" are integrated between squares of only a few centimeters in diameter (1/16 of the prototype size in 2011), and consume less than 70 milliwatts of energy. IBM's integration is indeed impressive.
What can such a chip do? The IBM research team has used the NeoVision2 Tower dataset that has been done with DARPA for demonstrations. It can identify people, bicycles, buses, trucks, etc. in the crossroads video of Stanford University's Hoover Tower at a normal speed of 30 frames per second, with an accuracy rate of 80%. In contrast, a notebook programming is 100 times slower to complete the same task, and the energy consumption is 10,000 times that of the IBM chip.
As with traditional computers using FLOPS (floating operations per second) to measure computing power, IBM uses SOP (synaptic operations per second) to measure the power and energy efficiency of such computers. The energy required to complete the 46 billion SOP is only 1 watt—as described at the beginning of the article, this capability is a supercomputer, but a small hearing aid battery can be driven.
The communication efficiency is extremely high, which greatly reduces energy consumption. This is the biggest selling point of this chip. Each core of TrueNorth has 256 neurons, each of which is connected to 256 neurons inside and outside.
(4) Google
In fact, on Google, I am very entangled, whether this is a new force, or a traditional company. But considering Google has been for so many years, I will put him in the tradition. Although the tradition is also very new. And Google's artificial intelligence related chip is the TPU. That is the Tensor Processing Unit.
The TPU is a dedicated chip designed specifically for machine learning applications. By reducing the computational accuracy of the chip and reducing the number of transistors required to implement each computational operation, the number of operations per second of the chip can be increased, so that a fine-tuned machine learning model can be run on the chip. Faster, and thus faster, for users to get smarter results. Google embeds the TPU accelerator chip into the board and uses the existing hard disk PCI-E interface to access the data center server.
According to Urs Holzle, senior vice president of Google, the current use of Google TPU and GPU will continue for a while, but it is also said that the GPU is too general and Google prefers chips designed for machine learning. The GPU can perform drawing operations and has many uses. The TPU is an ASIC, which is a special specification logic IC designed for specific purposes. Because it only performs a single job, it is faster, but the disadvantage is higher cost. As for the CPU, Holzle said that the TPU will not replace the CPU, and the TPU is only developed to deal with unresolved issues. But he also pointed out that he hopes that the chip market will have more competition.
If the AI ​​algorithm changes (logically the algorithm should change over time), do you want a chip that can be reprogrammed to accommodate these changes? If this is the case, another chip is suitable, it is the FPGA (Field Programmable Gate Array). FPGAs can be programmed to be different from ASICs. Microsoft uses some FPGA chips to enhance the AI ​​capabilities of Bing search engines. We naturally ask: Why not use an FPGA?
Google's answer is: FPGAs are much less efficient than ASICs because they can be programmed. The TPU has an instruction set that can be run on the TPU when the TensorFlow program changes, or when a new algorithm appears.
Now the answer to the question begins to emerge. In Google's view, energy consumption is an important consideration, and the data center is quite large, built around the world, including Finland and Taiwan. The higher the energy consumption, the higher the cost of operations, and the actual consumption of money will multiply over time. Google engineers compared the efficiency of FPGAs and ASICs and decided to choose an ASIC.
The second part of the problem is related to the instruction set of the TPU. This is a set of basic commands that exist in hard-coded form on the chip to identify and execute; in the chip world, the instruction set is the basis for computer operations.
When developing the TPU instruction set, it is specifically used to run TensorFlow, an open source software library for the development of AI applications. Google believes that if AI needs to make changes at the bottom, it is very likely that software will happen, and the chip should be flexible to accommodate this change.
The technical details of the TPU architecture have surprised many people who know the chip. Anandtech's Joshua Ho has an interesting theory: TPU is more similar to the third type of chip, the so-called Digital Signal Processor.
(5) Microsoft
This is another representative from soft to hard, Microsoft crouched for six years, to create a chip to meet the AI ​​generation. That is Project Catapult.
According to reports, this FPGA currently supports Microsoft Bing, in the future they will drive a new search algorithm based on deep neural networks - artificial intelligence based on human brain structure - when executing several commands of artificial intelligence The speed is several orders of magnitude faster than the average chip. With it, your computer screen will only be blank for 23 milliseconds instead of 4 seconds.
In the third generation of prototypes, the chip is located at the edge of each server, plugged directly into the network, but still creates an FPGA pool that any machine can access. This starts to look like something that is available for Office 365. Eventually, Project Catapult is ready to go live. In addition, Catapult hardware costs only 30% of the total cost of all other components in the server, and requires less than 10% of the operating energy, but it brings twice the original processing speed.
In addition, a series of chips from Xilinx, Qualcomm and China Cambrian are put into the research and development of AI. Let's press it for the time being. Let's take a look at the emerging AI chip forces.
Second, emerging forces(1) KnuEdge
KnuEdge is actually not a startup. It was founded by the former head of NASA and has been operating in a stealth mode for 10 years. KnuEdge recently emerged from the invisible model and let the world know that they were getting $100 million in investment from an anonymous investor to develop a new "neuron chip."
KUNPATH offers LambaFabric-based chip technology, and LambaFabric will perform neural network calculations through a completely different architecture than the GPUs, CPUs and FPGAs on the market today.
LambdaFabric is essentially designed to scale up to 512,000 devices in demanding computing environments with a rack-to-rack latency of only 400 nanoseconds and a low-power 256-core processor.
KNUPATH technology is based on biological principles and will redefine chip-level/system-level computing in the data center and consumer device markets.
Compared to other similar chips, this chip technology should provide 2x to 6x performance advantages, and the company has already earned revenue by selling their prototype system. Under the "KnuEdge Umbrella", KnuEdge consists of three separate companies, KnuPath provides their chips, KnuVerse provides proven military-grade speech recognition and verification technology, and Knurld.io is a developer that allows developers to simply Converged voice verification to their patented product's Public Cloud API service. KnuEdge claims that it now only needs to say a few words to the microphone to verify computers, networks, mobile applications and IoT devices. Wouldn't it be a great thing to remember the password again in the future?
(2) Nervana
This company has been acquired by Intel, but I think I still need to introduce this company. Nervana was founded in 2014, and San Francisco-based startup Nervana Systems has received $24.4 million from 20 different investment institutions, one of which is the highly respected Draper Fisher Jurvetson, DFJ ).
The The Nervana Engine (which will be available in 2017) is an ASIC chip specifically tailored and optimized for deep learning. This solution is achieved thanks to a new memory technology called High Bandwidth Memory, which has both high capacity and high speed, 32GB of on-chip storage and 8TB per second of memory access. The company currently offers an artificial intelligence service "in the cloud," which they claim is the world's fastest and currently used by financial services organizations, healthcare providers and government agencies, and their new chips will guarantee The Nervana cloud platform will continue to be the fastest in the next few years.
(3) Horizon Robot
The startup Horizon Robotics, founded in 2015 by Yu Kai, has received undisclosed seed funds from investors including Sequoia and legendary venture capitalist Yuri Milner. Later, he obtained joint investment in Morningside, Gaochun, Sequoia, Jinshajiang, Linear Capital, Innovation Works and Zhenge Fund. They are working on creating a one-stop artificial intelligence solution that defines “everything intelligence†to make life easier, more fun, and safer.
Horizon is committed to building a "brain" platform for artificial intelligence based on deep neural networks - including software and chips, to achieve low-power, localized solutions to environmental awareness, human-computer interaction, decision-making and other issues.
Among them, on the software side, Horizon has made a set of neural network-based OS, and has developed the “Hugo†platform for autopilot and the “Andersen†platform for smart homes, and has begun to gradually land. On the hardware side, the future horizon robot will also design a chip for this platform - NPU (Neural Processing Unit), to support its own OS, then the performance will increase by 2-3 orders of magnitude (100-1000 times).
On the Andersen platform, at the home fair in Shanghai in March this year, Horizon Robots demonstrated smart home appliances that cooperated with home appliance manufacturers, and other new products will be launched in the near future. On the Hugo platform, at the Singular Car Launch Conference on March 9 this year, Horizon Robots demonstrated the ADAS (First Aided Driving System) prototype system based on the Hugo platform for the first time. It is reported that the ADAS system of a well-known tier-1 auto parts supplier in the world is also determined to adopt the monocular sensing technology developed by Horizon.
(4) krtkl
Founded in 2015, krtkl is committed to creating "a tiny wireless computer used to create something completely different." Technicians will be obsessed with Snickerdoodle, a dual-core ARM processor, FPGA, WIFI, Bluetooth, starting at $65, "the platform with the smallest, most difficult, most affordable enabling robots, drones and computer vision." This product actually received more than $160,000 in funding through crowdfunding. The latest information is that they have received the initial version of Snickerdoodle and will ship soon. This development board is based on the XilinxZynq SoC, which integrates an ARM processor and a programmable FPGA. The user can even program it through a dedicated APP on the mobile phone for the I/O interface available to 230 users. The application is smart and compatible with many expansion boards, and its characteristics are as follows:
Select Zynq 7010 SoCchip, integrate dual-core ARM Cortex-A9@667Mhz processor and 430K LUT FPGA resources (can be promoted to Zynq LUT)
One of the highlights of this development board is that it not only supports the traditional MicroUSB program programming, terminal debugging equivalent energy, but also supports mobile terminal control, application officially provided Apps, through the Wi-Fi connection development board, users can download programs, pins Control, pin multiplexing and system control performance.
(5) Eyeeriss
Eyeriss is not actually a startup, but because it was developed by MIT and has received a lot of media coverage, we can't exclude it from this list. Eyeriss is a high-performance deep convolutional neural network (CNN) accelerator hardware. The architecture is as follows:
MIT said that the chip has 168 cores built in, which is designed to deploy a neural network, which is 10 times more efficient than a general-purpose mobile GPU. It also has high performance and can process data without using the network. The artificial intelligence algorithm is directly executed on the mobile device. It has the ability to recognize faces and languages ​​and can be applied to smart phones, wearable devices, robots, autopilots and other IoT applications.
The key to improving the performance of the Eyers chip developed by MIT is to minimize the frequency of data exchange between the GPU core and the memory (this process usually consumes a lot of time and energy), and the core in the general GPU. Usually a single memory is shared, but each core of Eyerss has its own memory.
In addition, the Eyerss chip can compress data before it is transmitted to each core, and each core can communicate directly with neighboring cores. Therefore, if you need to share data, the cores do not need to access the main memory. Can pass.
We are a professional manufacture in producing Carbdie Taps. We offer a complete range of taps in carbide, CPM and HSS-E.
we provied regular stock, and we also provide customization for your designs and logo. It is important to choose a professinonal manufacture to work with you, in order to communicate every details in the design. Our reputation has been built on quality, design and service – all at a competitive price. No matter you are a agent buyer or a factory source for self-use, we will be your most trusted partner.
Customized Carbide Taps are tools for processing internal thread. According to the shape, it can be divided into a spiral tap and a straight blade tap. According to the use environment, it can be divided into a hand tap and a machine tap. According to the specifications, it can be divided into metric, American and British taps. Taps are the primary tool for manufacturing operators to machine threads.
We can customize products according to customers' needs.
PRODUCT DETAIL:

PRODUCTING PROGRESS:

PAYMENT AND DELIVERY:

PRODUCT EQUIPMENT :
+
ABOUT US :
We are specialize in manufacturing PCD diamond tools and Carbide tools. Our major product inclulde PCD Inserts , PCD Reamers , PCD End Mills, PCD Taps, Cabide Inserts,Carbide Drills, Carbide Reams, Taps etc.,
We also offered customized cutting tools per drawings, and provide package according to customer requirements. We manufacture a series range of cutting tools for machining of Cast iron, Aluminium alloy and Non-Ferros metal, it is widely used in all major sectors like Automobiles, Engineering, Aerospace, Aviation and 3C industry. Premium quality of raw material is used in the production and strict examination during processing with advanced equipment, so our client are satisfied with our reliable quality and on-time delivery.
Our best selling of cutting tools include PCD Inserts, PCD End Mill, PCD Ball Nose Mill, PCD Reamer, Carbide Taps , Carbide End Mill, Special Form Cutter and many more. For these years we have been made a large forward in the technologies of manufacturing cutting tools. With high quality on performance and price, our product sells well both on domestic and overseas market. And we will always focus on the quality and best service, to make long business relationship.

quanlity control:
We have dedicated team of quality control and precise equipment to keep good and stable performance for our products and processing services.

Thread Milling Cutters,UNF Thread Milling Cutters,UNF Thread Milling Cutters,NPT Thread Milling Cutters
OPT Cutting Tools Co., Ltd. , https://www.optdiamondtoolss.com