Support vector machine is a machine learning method developed on the basis of statistical learning theory [1]. By learning the precise information near the interface between categories, it can automatically find those support vectors that have better ability to distinguish the classification Therefore, the classifier constructed by this method can maximize the interval between classes, so it has better generalization performance and higher classification accuracy. Because support vector machines have the advantages of small samples, nonlinearity, high dimensionality, avoiding local minimum points and over-learning phenomena, they are widely used in fault diagnosis, image recognition, regression prediction and other fields. However, if there is no effective feature selection for the samples, the support vector machine often has too long training time and low classification accuracy when it is classified. This is precisely because the support vector machine cannot use the confusing sample classification information. Therefore, feature selection is an important link in the classification problem. The task of feature selection is to remove redundant features that are not useful for classification and those repeated features with similar classification information from the original feature set, which can effectively reduce the feature dimension, shorten the training time, and improve the classification accuracy.
The current feature selection methods mainly include principal component analysis, maximum entropy principle, rough set theory and so on. However, because these methods are mainly based on complicated mathematical theory, there may be objective qualifications such as derivation and function continuity in the calculation process, and it is necessary to set search rules to guide the optimization search direction when necessary. As an extremely robust and intelligent identification method, genetic algorithm directly operates on the optimization object, there is no limitation of specific mathematical conditions, and it has excellent global optimization ability and parallelism; and because genetic algorithm uses probability In the automatic search process, you can independently obtain clues related to optimal search, and after learning, you can adaptively adjust the search direction without determining the search rules. Therefore, genetic algorithms are widely used in knowledge discovery, combinatorial optimization, machine learning, signal processing, adaptive control and artificial life.
Feature selection based on improved genetic algorithm
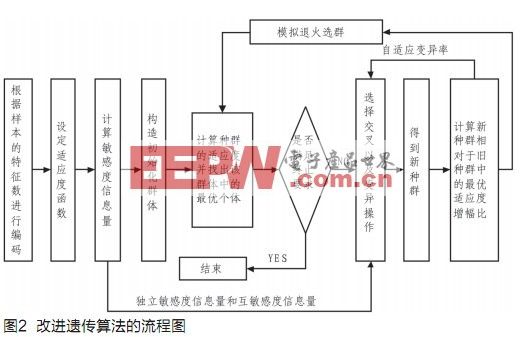
Genetic algorithm is a newly developed search optimization algorithm [2 ~ 5]. The genetic algorithm starts from any initial biological population, and through random selection, crossover, and mutation operations, generates a new generation of population with new individuals that are more adapted to nature, making the evolutionary trend of the population toward the optimal direction. Figure 1 shows the block diagram of the standard genetic algorithm.

The traditional genetic algorithm has shortcomings of premature convergence, non-global convergence, and slow late convergence. Therefore, this paper proposes an improved genetic algorithm that can adaptively adjust the mutation rate during evolution and use simulated annealing to prevent prematurity. The algorithm uses sensitivity information to effectively control genetic operations. Figure 2 is a flowchart of the improved genetic algorithm.
Chromosome coding and fitness function
The so-called coding refers to converting the solution space of the problem into a search space that can be handled by the genetic algorithm. In the feature selection problem, binary encoding is often used, so that each binary is a chromosome, and the number of bits is equal to the number of features. Each bit represents a feature, a 1 on each bit indicates that the feature is selected, and a 0 indicates that it is not selected. Each generation population consists of several chromosomes.
The fitness function is an extremely important part of the entire genetic algorithm [6]. A good fitness function can make the chromosome evolve to the optimal individual, which determines whether the premature convergence and slowness can be reasonably coordinated in the entire optimization process. End these contradictions. Since this article is directed to the feature selection problem of support vector machines, we consider the two parameters of classification accuracy and the number of unselected features as the independent variables of the function, and use the classification accuracy as the main measurement criterion. Numbers are secondary criteria. Therefore, the following fitness function is established:
Where C is the classification correct rate, the number of unselected features, and a is the adjustment coefficient, which is used to balance the influence of the classification correct rate and the number of unselected features on the fitness function, and the coefficient also reflects the least The principle of obtaining a large classification accuracy rate for the characteristics of , in this paper, a is taken as 0.00077. It can be seen from the above formula that the higher the classification accuracy, the greater the number of unselected features, and the greater the fitness of the chromosome.
Select operation
The selection operation needs to select some excellent individuals from the original population for crossover and mutation according to certain rules. The selection principle is based on the evaluation of individual fitness. The purpose is to avoid gene loss and improve global convergence and computational efficiency. In this paper, the first 40% of the best individuals in the entire population are retained to ensure that there are enough good individuals to enter the next generation. The remaining 60% of individuals are selected using the roulette algorithm, which can make up for the remaining 40. The local optimal solution brought by% individuals is not easy to be eliminated, which is conducive to maintaining the diversity of the population.
Crossover and mutation operations based on the amount of sensitivity information
The independent sensitivity information quantity Q (i) refers to the fitness value Allfitness calculated when all features are selected and the fitness value Wfitness (i) calculated when only the feature i is not selected according to formula (2) ) The calculated value. The independent sensitivity information characterizes the sensitivity of the fitness to whether the feature i is selected.
The mutual sensitivity information amount R (i, j) can be obtained from equation (3), and the mutual sensitivity information amount reflects the approximate influence degree between the feature i and the feature j on the fitness.
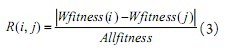
The function of the crossover operation is to generate new individuals containing some of the original fine genes by swapping several bits between two chromosomes. From equation (3), it can be known that the mutual sensitivity information can be used as a measure of similar classification information between different features, so the mutual sensitivity information can be substituted into equation (4) to calculate the probability of chromosome crossing at the first position b (i), in formula (4), i and j represent feature i and feature j, respectively, which is the length of chromosome. b (i) is the normalized amount of the mutual sensitivity information of feature i relative to all other features, which reflects the sum of the feature and other features in the similar information. Corresponding to the chromosome, b (i) can be regarded as the correlation between the i-th position of the chromosome and the entire chromosome in genetic information. The smaller b (i) means the greater the correlation, the i-th position is related to the entire chromosome The closer the contained genetic information, the smaller the probability that this bit is a split point. Since b (i) is a normalized quantity, the roulette algorithm can be used to select a crossing point.
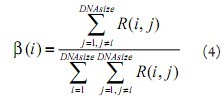 Mutation operation is an important means to introduce new species, which can effectively increase the diversity of individual populations. In this paper, the mutation rate Pm adopts the optimal fitness increase ratio between two adjacent generations as an independent variable for adaptive adjustment, as shown in equation (5). When the fitness increase ratio increases positively, a smaller increase ratio can maintain the mutation rate at a medium level, and the mutation rate decreases slowly as the increase ratio increases, so that it can have a certain number of new individuals. Inhibit the production of too many bad chromosomes to ensure that the evolution of excellent chromosomes is stable enough; and when the fitness increase ratio is increased in the reverse direction, a smaller increase ratio can obtain a higher mutation rate, and the mutation rate is also accompanied by the increase ratio. Slowly increase to ensure that there are enough chromosomes to mutate and steadily speed up the evolution.
Mutation operation is an important means to introduce new species, which can effectively increase the diversity of individual populations. In this paper, the mutation rate Pm adopts the optimal fitness increase ratio between two adjacent generations as an independent variable for adaptive adjustment, as shown in equation (5). When the fitness increase ratio increases positively, a smaller increase ratio can maintain the mutation rate at a medium level, and the mutation rate decreases slowly as the increase ratio increases, so that it can have a certain number of new individuals. Inhibit the production of too many bad chromosomes to ensure that the evolution of excellent chromosomes is stable enough; and when the fitness increase ratio is increased in the reverse direction, a smaller increase ratio can obtain a higher mutation rate, and the mutation rate is also accompanied by the increase ratio. Slowly increase to ensure that there are enough chromosomes to mutate and steadily speed up the evolution.
In the formula, dis refers to the increase ratio of the optimal fitness of the new population relative to the optimal fitness of the original population. Both j and k are adjustment coefficients in the interval (0, 1). In this paper, j and k are taken as 0.65 and 0.055 respectively.
The amount of independent sensitivity information reflects the amount of classification information contained in a single feature to a certain extent. If the amount of independent sensitivity information is small, it means that most of the information contained in the feature is not helpful for classification, that is, after the mutation of this gene position The superiority of the entire chromosome has little effect, and the probability of mutation is reduced accordingly. Therefore, the q (i) obtained after normalizing the independent sensitivity information amount is the probability that the feature i is selected as the mutation point. The specific selection method of the mutation point is: a chromosome is traversed according to the number of chromosomes, and in this cycle, the mutation rate Pm determines whether a mutation bit occurs. If there is a need to generate a mutated bit, the selection is made according to the roulette algorithm based on q (i).
Simulated Annealing
After each round of evolution is completed, it is necessary to decide to enter the next evolutionary population. If too many superior populations are used as parents, it will make the algorithm converge prematurely or search slowly. Literature [7] pointed out that the simulated annealing algorithm can accept the inferior solution with a certain probability to jump out of the local extreme value region and eventually tend to the global optimal solution. Therefore, the above-mentioned optimal fitness increase ratio can be used as an energy function, Use the simulated annealing Meteopolis criterion to select the population to be evolved. In order to fully evolve each population and prevent the loss of the optimal solution, the strategy of setting the annealing step size is adopted here to realize simulated annealing cluster selection. The strategy is specifically to make the annealing step count the number of times that the same kind of group is used as a parent. Once a better population is generated, the annealing step is set to zero and recounted. If the accumulated annealing step exceeds a certain threshold, it enters the simulated annealing cluster selection stage. The accumulation of annealing steps to a certain number means that the evolution of the original population has stalled, and a simulated annealing algorithm is needed to get rid of this stagnation. If the increase ratio is greater than zero, it means that the new population is better than the original population. At this time, the new population is completely accepted to enter the next round of evolution; otherwise, the new population is inferior to the original population, and the newer population is accepted with a certain probability p [ 8] Enter the next round of evolution. The acceptance probability p is determined jointly by equations (6) and (7), where dis is the increase ratio, T (s) refers to the temperature parameter, and T0 and s are the initial temperature and the number of iterations, respectively.
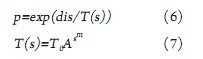
The parameters of the above two formulas should meet the requirements of evolution on the acceptance probability. That is, the greater the increase than the negative increase, the faster the acceptance probability decreases, but the acceptance probability should decrease slowly as the number of iterations increases. Doing so can ensure that within a limited number of iterations, a new population with better fitness will enter the next round of evolution to achieve the purpose of reducing the amount of calculation and optimizing the population to be evolved. In this article, T0 = 0.2, A = 0.9, m = 0.5.
Verification and analysis of examples
The UCI database is commonly used to compare the classification effects of various methods, so it can be used to verify the classification effect of the algorithm on the support vector machine [9] [10]. Literature [11] used the German, Ionosphere and Sonar data in the UCI database as the experimental objects. In order to facilitate comparison with several methods used in the literature [11], this article also uses these three data for experiments, and according to The ratios described in the literature divide various types of data into corresponding training samples and test samples.
Using the support vector machine as the classifier (the penalty parameter is 13.7 and the radial basis kernel function parameter is 10.6) under the conditions of a population size of 30, a crossover rate of 0.8, and an initial variation rate of 0.1, the selected data is classified. Figure 1 shows the comparison of the classification effects of this algorithm and several algorithms in [11]. Table 2 gives the final selection results of the three data. There are four methods in Table 1: Method 1: Use this algorithm; Method 2: Use NGA / PCA method; Method 3: Use PCA method; Method 4: Use simple genetic algorithm.

Since the algorithm in this paper aims to maximize the classification accuracy rate with the least number of features, it can be seen from Table 1 that the algorithm in this paper has advantages over the other three methods in feature selection number and classification accuracy rate. Because the NGA / PCA algorithm is an improvement for the shortcomings of the simple genetic algorithm and the principal component analysis method, its performance is better than the simple genetic algorithm and the principal component analysis method, so the classification effect of the algorithm in this paper is better than the NGA / PCA algorithm. It also shows that the algorithm can better solve the feature selection problem of support vector machines.
Conclusion
By comparing with other methods, the classification effect of the algorithm in this paper has been fully verified, and it also shows that the algorithm has excellent generalization ability and the effectiveness of genetic operations under the guidance of the amount of sensitivity information.
The design of the fitness function is very important. It directly affects the quality of the final result and the convergence of the algorithm. Therefore, the focus of the problem to be solved should be considered in the design of the fitness function.
The accuracy of classification depends not only on reasonable feature selection, but also on parameter optimization of support vector machines. Only under the premise of reasonable feature selection and parameter optimization, the support vector machine classifier can exert the best classification effect.
Because the algorithm can solve the feature selection problem of the support vector machine, it has been applied to the fault diagnosis of the digital circuit board based on the support vector machine, and has achieved good results.
Led Digital Tube Light use
LED chip and PC pipe, anti-aging, anti-UV, long life, energy saving, bright
color. Lighting effects are monochrome, color changes, 7 colors changes, three
of the changes, six changes, and changes in Section 12 of the changes.
Through own chip microcomputer programming, enabling many sources to produce
colors and the composition of the changes in dynamic, vertical stratification
chase scanning, water, expansion, graded, synchronization, and other changes in
procedures may also require programming control .
Widely used in bridges, squares, building contour, cross-Street corridor in the
air, the outline of buildings, road
lighting, all kinds of lighting billboards, windows, the stage, buildings,
hotels, decoration, is the leading city lighting engineering products, night
results particularly eye-catching, and the glorification of cities, landscapes
shape a special significance.
Led Digital Tube,Led Digital Tube Light,Digital Led Tube,Digital Tube
ZHONGSHAN G-LIGHTS LIGHTING CO., LTD. , https://www.glightsled.com