There have been many studies using neural network generation programs, but the current work is basically based on strict semantic restrictions. Rice University researcher Vijayaraghavan Murali and others will make an oral report on ICLR 2018 to introduce their new research and generate a strongly typed program similar to Java based on uncertain syntactic conditions.
AML
Java is still a bit complicated for program generation. So the researchers made some simplifications to Java and designed a new language AML. AML portrays the essence of API usage in Java-like languages.
AML uses a collection of limited API data types, which are also finite collections specified by API method names (including constructor). The type signature of method a is represented by (Ï„1, ..., Ï„k) -> Ï„0.

AML syntax
Where c is the variable, x, x1, ... represent the variable, and let is used for the variable binding.
Training data
The training data is an annotated program:
{(X1, Prog1), (X2, Prog2), ...
Among them, Prog1, Prog2... are AML programs. X1 and X2 are labels. After training, the model will generate a program based on the tag, so the tag should contain information about the tag.
What is the specific information?
First, AML is primarily a language designed based on API calls, so API calls are important information.
Second, AML is born out of Java as a statically typed language, so type is also important information.
In theory, a given API call and type can be used to generate a program. But in fact the model is not so smart, sometimes it needs some extra information, some keywords.
Therefore, the labels are divided into three categories:
X call
X type
X keyword
Among them, the keywords are mainly based on the type and calling method named CamelCase segmentation. For example, readLine will be split into 2 keywords read and line.
sketch
As described in the previous section, the training data is the label (X) and the AML program (Prog). However, researchers did not directly learn the relationship between tags and procedures. Because the program contains some low-level information, this information does not matter, and does not need to learn. For example, the specific variable naming, replacement, does not affect the semantics of the program (α-equivalent in λ calculus). Therefore, the program needs to be converted and converted into a representation of the high-level structure and shape (control structure, API call order, parameter type, return value type) of the program. Based on this idea, the researchers abstracted some low-level information (variable naming, basic operations) in the program, which turned the program into a sketch and learned the probability distribution on the sketch based on the label. Then, use the combined method to visualize the sketch into a type-safe AML program (through a type-directed random search process).
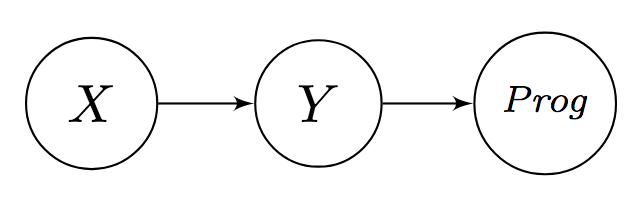
Bayesian network of Prog, X, Y
Among them, Yi = α (Progi), Y (sketch) syntax is as follows:
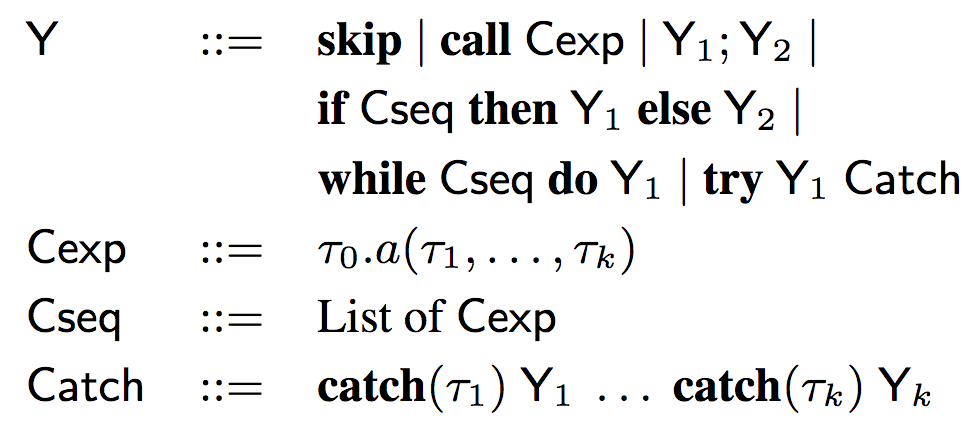
As you can see, the syntax of the sketch is similar to the syntax of AML, abstracting out the variable names (x, x1, etc.), retaining the control structure, type information, and API calls.
Comparing the syntax of the sketch with the syntax of the AML, the definition of the alpha function (the operation of abstracting the sketch from the program) is self-explanatory:

GED
As mentioned earlier, the model will learn based on sketches:
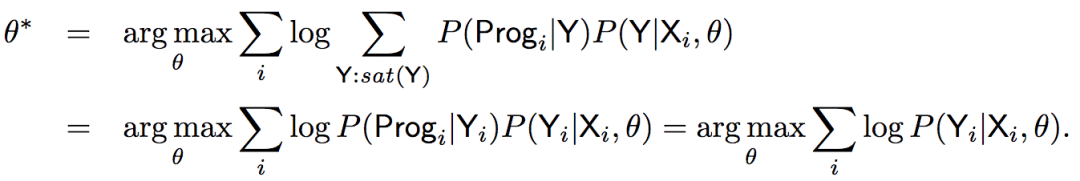
The above formula shows that in the end we need to calculate:
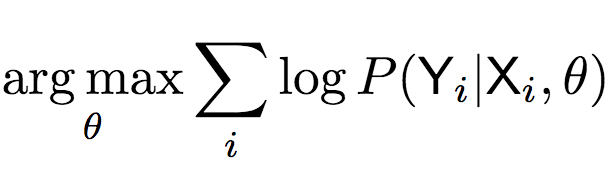
To calculate the above formula, the researchers proposed a Gaussian Encoder-Decoder (GED) model, introducing a latent vector Z to randomly connect labels and sketches:
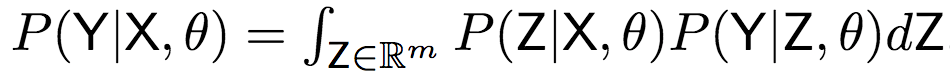
Below we take the code X call as an example to illustrate how the encoder works.
First, each element X called by X is called, i is converted to a one-hot vector representation, denoted as X' call, i. Then, by calling X' in the following formula, i
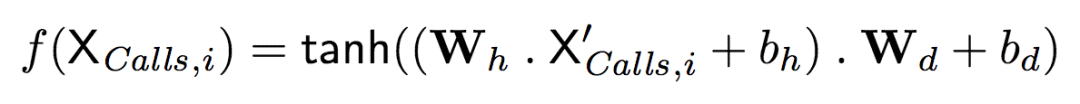
XCalls, i is X call, i
Where h is the number of neural hidden units, Wh ∈ R|calls | xh, bh ∈ Rh, Wd ∈ Rh xd, bd ∈ Rd are the weights and offsets of the network, which can be learned through training.
Based on f, P(X | Z, θ) can be calculated
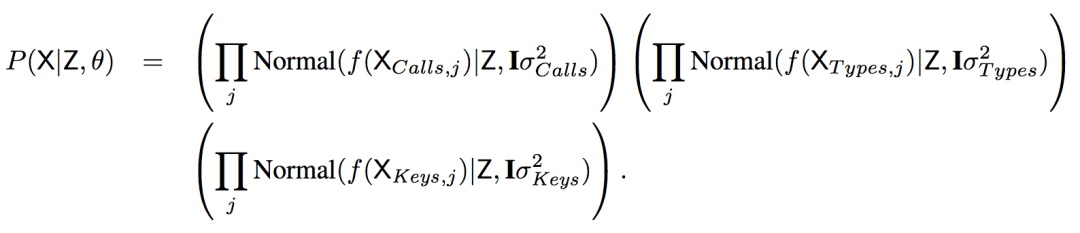
That is, the X-coded value is sampled from a high-dimensional normal distribution centered at Z.
The calculation of P(X | Z, θ) requires coding, and the calculation of P(Y | Z, θ) is the opposite, and decoding is required.
Sketch Y can be seen as a tree structure.
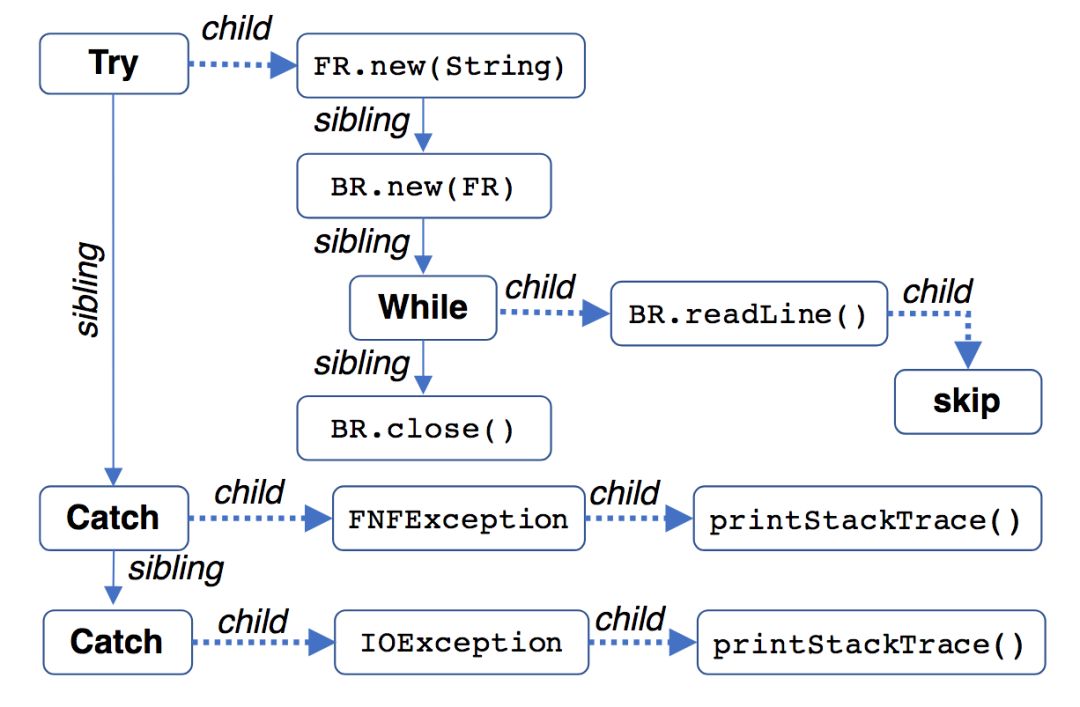
The researchers used a top-down search method to recursively calculate the output distribution yi from the top of the tree, all the way down. The “road†of “all the way down†is called the production path by the researchers. The production path is defined as the sequence of ordered pairs <(v1, e1), (v2, e2), ..., (vk, ek)>, where vi is the node in the sketch (ie the item in the grammar), ei The type of edge that connects vi and vi+1. Specifically, the edges include two types: sibling (brothers and sisters, solid lines in the above image) and children (children, dashed lines in the above image).
For example, there are 4 production paths in the above picture:
(try,c), (FR.new(String),s), (BR.new(FR),s), (while,c), (BR.readLine(),c), (skip,·)
(try,c), (FR.new(String),s), (BR.new(FR),s), (while,s), (BR.close(),·)
(try,s), (catch,c), (FNFException,c), (T.printStackTrace(),·)
(try,s), (catch,s), (catch,c), (IOException,c), (T.printStackTrace(),·)
Where · indicates the end of the path. In addition, for the sake of brevity, the above paths are omitted (root, c), sibling and child are represented by s and c, and some class names are abbreviated.
Given a sequence of Z and a production path Yi = <(v1,e1), ..., (vi,ei)>, in order to simplify the calculation, it is assumed that the next node in the path depends only on Z and Yi, thus The decoder can calculate the probability P(vi+1 | Yi, Z) using a single inference step. Specifically, the decoder uses two circular neural networks, one for the c-edge and one for the s-edge.
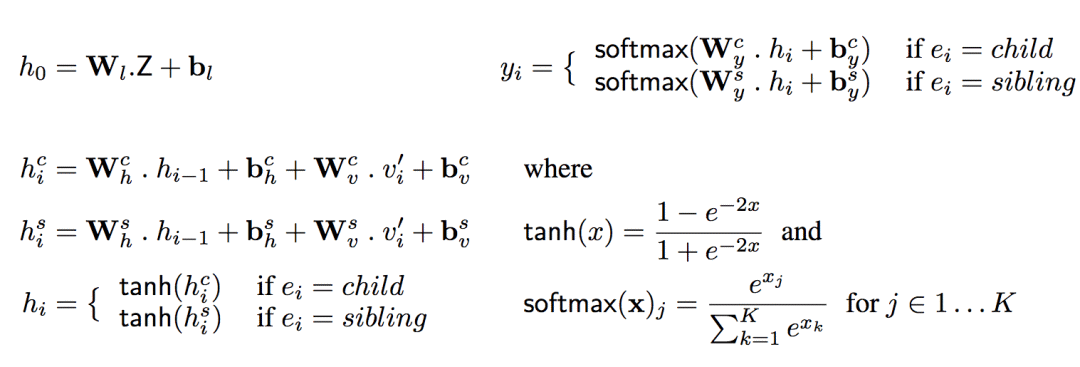
Where v'i is the one-hot vector into which vi is converted. h is the number of hidden units of the decoder, and |G| is the output vocabulary of the decoder. Whe and bhe are the hidden state weights and offset matrices of the decoder, Wve and bve are input weights and offset matrices, Wye and bye are output weights and offset matrices (e is the type of edges). Wl and bl are "boost" weights and offsets, lifting the d-dimensional vector Z to the decoder's high-dimensional hidden space h.
Visualization
The researchers visualized the clustering of 32-dimensional latent vector spaces. The researchers get the label X from the test data, then sample the latent vector Z from P(Z | X) and sample the sketch Y from P(Y | Z). Then use t-SNE to reduce the dimension Z to 2 dimensions, then mark each point based on the API usage in Y. The figure below shows this 2-dimensional space, with each label corresponding to a different color.
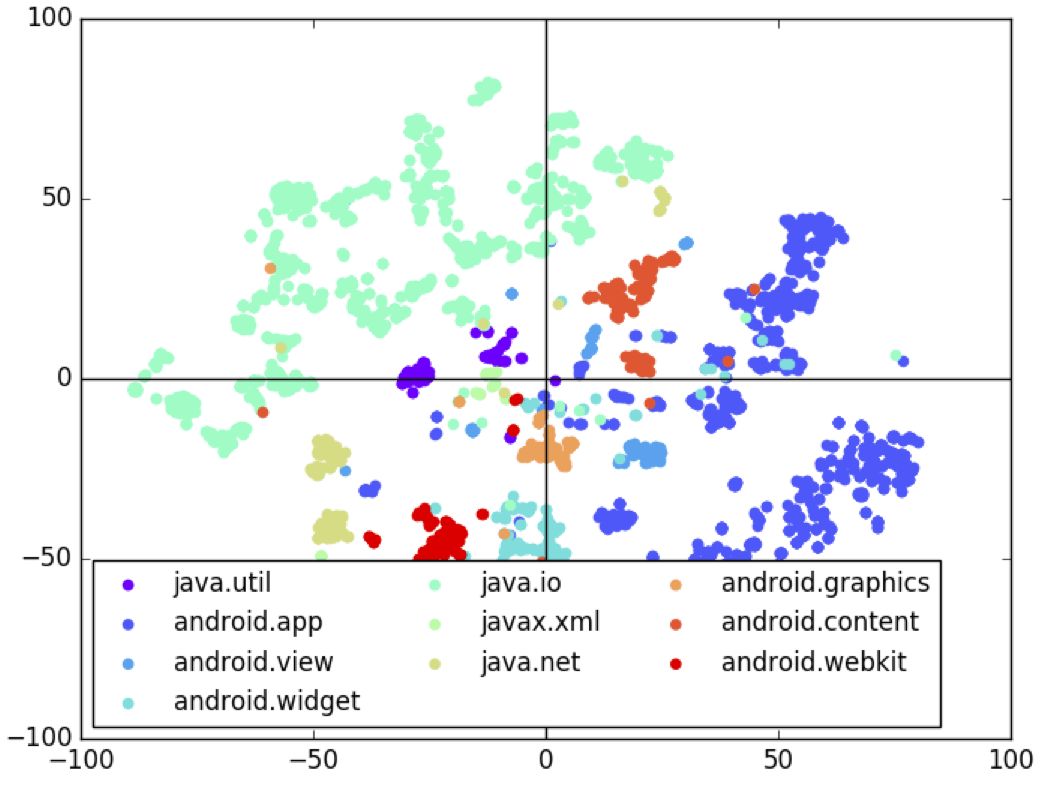
From the above figure, we can clearly see that the model learns the clustering of the latent space well according to the API.
Quantitative test
The researchers tested based on 1500 Android apps (collected from the web). The researchers used JADX to decompile the 1500 Android application installation files (APKs) to 100 million lines of source code and extracted 150,000 Java methods from them. The researchers then converted the 150,000 Java methods into AML programs. Then, sketch Y and X calls, X types, and X keywords are extracted from the AML program for model training. Among them, 10,000 AML programs were randomly selected as the verification set and the test set.
In theory, verifying the correctness of the generator requires that the output of all inputs to the validator match the expectations. However, this is an undecidable problem. Therefore, the researchers turned to some indirect criteria to measure.
Expect AST
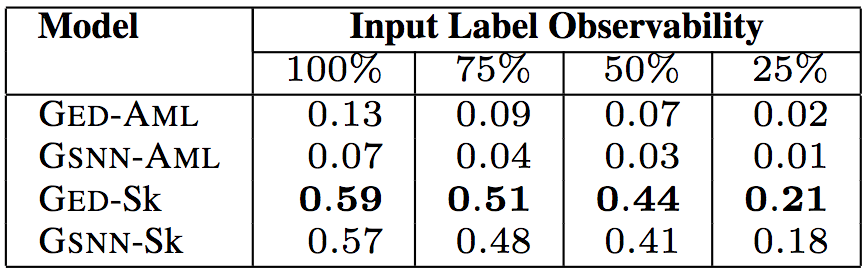
The degree of similarity of the API call order (specifically, the researchers used the average minimum Jaccard distance)
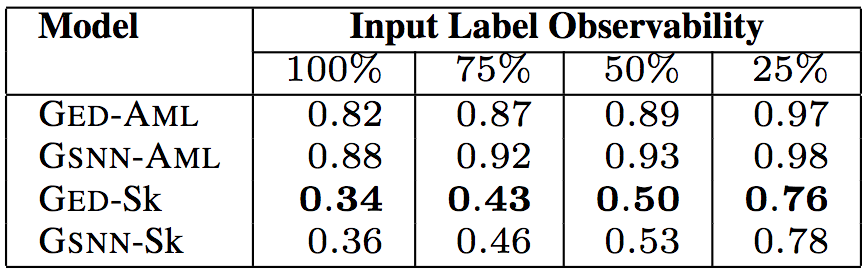
The similarity of API calling methods (also based on the average minimum Jaccard distance)
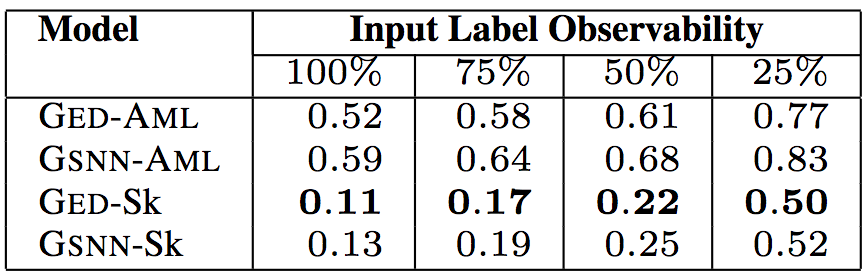
Number of statements
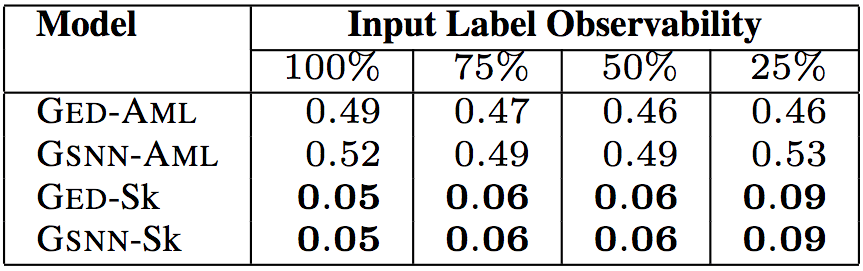
Number of control structures (for example, branch, loop, try-catch)
In the above five tables, "Input Label Observability" indicates the proportion of information on the input tags (API calls, types, keywords) provided by the test data. The researchers tested 75%, 50%, and 25% of the observability, with a corresponding median of 9, 6, and 2, respectively. In this way, the researcher can evaluate the predictive power of the model given a small amount of information about the code.
The table below shows the model's performance on unseen data at 50% observability.
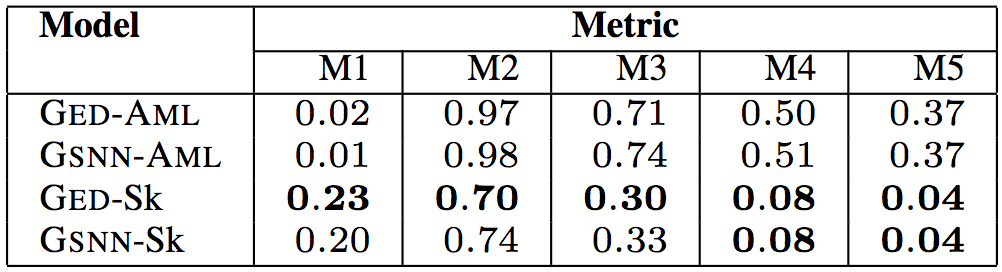
In the above six tables, in the “Model†column, GED is the model used by the researchers, and GSNN (Gaussian Stochastic Neural Network) is the most advanced conditional generation model (Sohn et al. proposed in 2015). To verify the effectiveness of the sketch learning, the researchers performed an ablation test. The -Sk suffix is ​​a sketch-based learning model, and the -AML suffix is ​​a model that learns directly based on the program.
The test results show that the model proposed by the researchers is the best GED-Sk, which exceeds the current state-of-the-art model GSNN. In addition, GSNN-Sk performs well, and models that learn directly based on programs perform poorly. This shows that sketch learning is the key to conditional program generation.
Qualitative test
In addition to quantitative testing, the researchers also conducted qualitative tests.
File reading and writing
Researchers hope that Bayou can generate a program to write to a file. Think about it, if you want to instruct Bayou to generate a program to write to a file, what tips would you give? The minimum hint should be two keywords, write, file, or even just a type FileWriter. Bayou is not so smart, but its performance has been quite eye-catching. The researchers' input to Bayou is just a type and a keyword, almost the minimum information:
X type = {FileWriter}
X call = {write}
X keyword = {}
Bayou generated the following program (selected from top-5):
BufferedWriter bw;
FileWriter fw;
Try {
Fw = newFileWriter($String, $boolean);
Bw = newBufferedWriter(fw);
Bw.write($String);
bw.newLine();
Bw.flush();
Bw.close();
} catch (IOException _e) {
}
Note that although the input only provides the FileWriter type, the program uses BufferedWriter, because in Java, file reads and writes are often based on buffers. Bayou learned this on his own. In addition, Bayou also correctly flushes the buffer before closing the file.
Android dialog
The researchers hope to generate a program that sets the title and information of the Android dialog. The input given by the researchers has reached a minimum:
X type = {}
X call = {}
X keyword = {android, dialog, set, title, message}
The generated program is as follows:
Builder builder2;
Builder builder1;
AlertDialog alertDialog;
Builder builder4;
Builder builder3;
Builder1 = newBuilder($Context);
Builder2 = builder1.setTitle($String);
Builder3 = builder2.setMessage($String);
Builder4 = builder3.setNeutralButton($String,
$OnClickListener);
alertDialog = builder4.show();
Although not specified in the input information, Bayou intelligently used the helper class AlertDialog.Builder. In addition, Bayou also added a button to the dialog box, because Bayou learned that the Android dialog box is often equipped with a button (usually used to close the dialog box).
Preview shot
The last example is a program that produces a preview shot. The given input can be said to be minimal:
X type = {}
X call = {startPreview}
X keyword = {}
The program generated by Bayou:
Parameters parameters;
Parameters = $Camera.getParameters();
parameters.setPreviewSize($int, $int);
parameters.setRecordingHint($boolean);
$Camera.setParameters(parameters);
$Camera.startPreview();
This example fully embodies the intelligence of Bayou. First, Bayou automatically recognizes that startPreview belongs to the camera API. Second, before starting the preview, Bayou first acquired the camera parameters and then set the preview display size. This is the recommended practice for the Android camera API documentation!
Implementation details
The researchers named the entire system Bayou, which consists of two parts, a GED based on TensorFlow, and a sketch abstraction and composition based on the Eclipse IDE.
The researchers used cross-validation based on grid search to select the model with the best performance.
The hyperparameter settings are as follows:
Encoder: Call 64 units, type 32 units, and keywords 64 units.
Decoder: 128 units.
32-dimensional latent vector space.
Mini-batch size: 50.
Adam optimized, the learning rate is 0.0006.
Epoch: 50.
The training of the entire model takes about 10 hours (AWS p2.xlarge, K80, 12G Ram)
Conclusion
This is the first study to use a neural network based on an indeterminate conditional generation program. Future IDEs may provide extremely intelligent code completion based on similar models.
Edge Sealing Machine,Automatic Sealing Machine,Heat Sealing Machine,Automatic Edge Sealing Machine
Dongguan Yuantong Technology Co., Ltd. , https://www.ytbagmachine.com